

What Cloud Marketplaces Do and Don’t Do
Not long ago, we observed here in our blog that the critical insights that drive business value come from data that is both (1) fast and (2) reliable.

It’s time to shake up the status quo of external data vendor management.
Data engineers are not vendor managers.
But when an executive’s favorite Tableau dashboard isn’t populating because something is wrong with its data source and he sends a high importance email to the engineering team, someone quickly becomes a vendor manager for the next 48 hours.
Suddenly, it’s a single engineer’s job to reach out to the data vendor as quickly as possible, which is often a challenge as email is the main communication method. If she’s lucky, someone on the supplier side may reach out that day, but even then, if she’s lucky enough to get a response, it simply directs her to a generic customer assistance email account. Or she’ll end up with a 1-800 service phone number and spend three hours of her day on hold, only to be directed back to the person she started with.
Data vendors supply data access, but are not usually responsible for the state of the data once it’s delivered. So your data engineer now spends her evening hours digging through repositories and logs, only to find out that the vendor changed a schema without notice. At this point, it’s critical to pause and remember: repeatedly completing tedious work that is not your core competency is incredibly demotivating and can lead to burnout.
The next morning at work, she reaches back out to the supplier to let them know what happened, only to be met with an “okay” sent from iPhone email response. This isn’t because her supplier contact is rude, or doesn’t care about her account. But her contact does know that they can’t support each individual licensed client with access to their data, and that they’re big enough–in stature and popularity in the market–that customer service doesn’t have to be their focus to keep bringing in revenue.
So the exec is satisfied, the pipeline is repaired, the schema has been updated, and all is well…right? But no one is accounting for the lost hours the engineer spent putting out this fire. Suddenly, your data engineer spent all of her working hours–and even more–acting as a vendor manager. None of her other work for the day was touched, and your company just paid her an engineer’s salary to sit on hold for three hours. But it’s not the exec or the engineer at fault here, or even the data supplier. It’s the status quo, and it needs a transformation to account for this overlooked, albeit common, problem data engineers face when working with external data.
If you’ve made it this far, you might be squinting your eyes a bit and thinking to yourself, well, sometimes these things happen as a cost of doing business. A few hours of an engineer’s time are negligible in the grand scheme of things. And sure, that’s the case if your organization is a startup with 13 employees who wear many hats and are often pulled in a thousand different directions. But let’s do some quick math.
Let’s say our engineer makes $350,000 annually, which is about $179 an hour. In our example, our engineer spent 10 hours working on the pipeline problem, with about 4 of those hours spent simply trying to contact someone for help. That’s $1,790 worth of data engineering work lost that day, which is pennies for large corporations.
But now let’s think about that at scale. Most companies use 3-5 external data sources at minimum to support their critical business functions and decision-making. For easy math, let’s assume you have a 1:1 engineer to data source ratio. With 5 data sources, that same issue could cost you $8,950 if each of them has one issue per year. But again, external data doesn’t come cleanly packaged and ready to go. Conservatively, if each data source only has one issue a quarter, that’s $35,800. Monthly? $107,400. It’s easy to see how this can very quickly spiral into a five- or six-figure hidden cost.
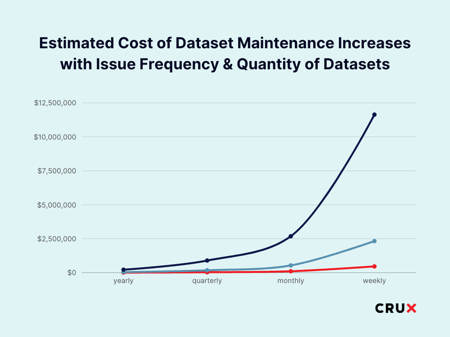 And that’s before even considering scale, and adding more datasets to the pipeline. Or before considering the financial implications of reallocating your data engineering resources from mission critical, revenue-driving work. Or accounting for hiring more engineers, or even a vendor manager to grow with your data pipeline. Frankly, these numbers don’t exist at scale because no one has studied this problem in-depth, because it’s accepted as a status quo cost of business. But it doesn’t have to be anymore.
And that’s before even considering scale, and adding more datasets to the pipeline. Or before considering the financial implications of reallocating your data engineering resources from mission critical, revenue-driving work. Or accounting for hiring more engineers, or even a vendor manager to grow with your data pipeline. Frankly, these numbers don’t exist at scale because no one has studied this problem in-depth, because it’s accepted as a status quo cost of business. But it doesn’t have to be anymore.
No matter what line of business you’re in, adjusting your budget to allocate more money for ROI drivers and less on overhead costs–from your tech stack to employee investments–is always seen as good work. By identifying how much time your data engineering team spends on vendor management and investing that money in a solution that scales, you’ve opened up an allowance for that brilliant data scientist your team has been eyeing, a new data platform that makes onboarding datasets easier, a tool that helps transform and combine data, or even one that does all of those things.
Making sure your data engineers are able to handle only their core responsibilities also means that you’re getting more bang for your buck when it comes to human resources, and it expands your team capacity. All of that is possible with Crux. We started where you are, with the same problems and frustrations, and now we’re able to offer the solution. Our platform is built from a place of empathy, because we’ve been there before.
With Crux, you can reallocate that hidden vendor management cost into our technology, and let us handle the heavy lifting when it comes to your external data, freeing up your data engineers to do what they do best. Gone are the days of accepting the status quo as your only option, because now Crux is offering up the solution. We’re already connected to 265+ data suppliers–simply connecting to a single Crux pipeline opens up that access and all your vendor management issues will vanish.
Want to learn more? Reach out to me at chris.maurer@cruxinformatics.com to connect with me on removing vendor management from your data engineering workload.


Not long ago, we observed here in our blog that the critical insights that drive business value come from data that is both (1) fast and (2) reliable.

This past year has been exciting, representing the dawning of a new age for artificial intelligence (AI) and machine learning (ML)—with large...

How do you get white-glove customer service from a major data supplier?