

What Cloud Marketplaces Do and Don’t Do
Not long ago, we observed here in our blog that the critical insights that drive business value come from data that is both (1) fast and (2) reliable.

External data can no longer be left out when we talk about big data as a whole.
Anyone who has had formal education or professional experience with data is familiar with the four Vs of big data–volume, velocity, variety, and veracity. A quick google search will yield pages upon pages of results explaining what these four Vs are and why they’re relevant.
The four Vs of big data aren’t new, but external data integration is. As our CEO Will Freiberg likes to say, “external data got left behind.” We think that’s true. Historically, big data has referred to any mass amount of data analysts can use to glean insights, trends, and patterns. While that definition can envelope external data, it wasn’t created with it in mind.
Only recently with the boom of ESG data, social media, and constant internet access has external data started seeing the same exponential growth as internal data usage. Because of that, we think the four Vs of big data are ready for a refresh.
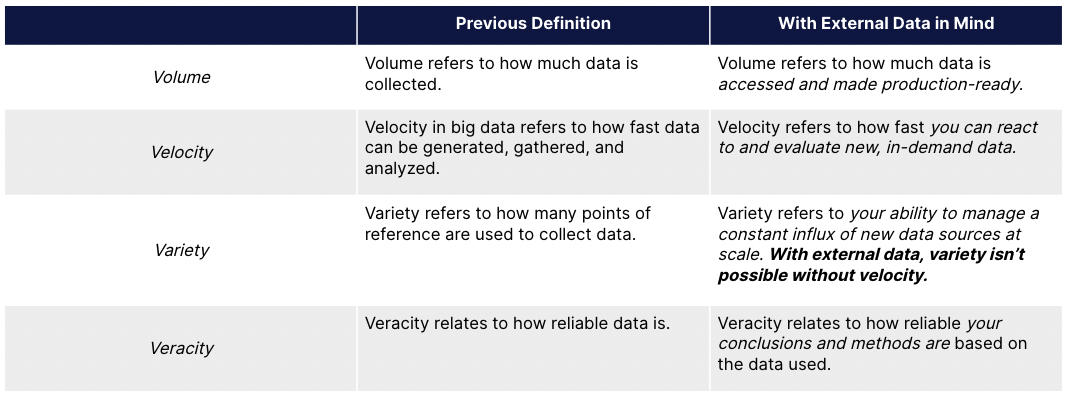
Originally, the volume of big data was simple: the volume of data points collected. And that still works if you don’t consider external data. An organization’s ability to collect more and more data points gives them more context, and in return, more informed decisions can be made.
But in today’s world of external data, volume is infinite. Everything anyone touches online is a new source full of data points that grow by the second. Think about how many web pages, social media sites, or other apps you use in one day. Each of those is gathering its own data, and in turn, that data is supplied to anyone who wants to use it. There is no shortage of information out there created outside of the four walls of your company.
What matters for external data is the volume of data your business actually accesses and then transforms into a production-ready resource for internal consumption. The volume of data points is no longer even a consideration–it’s an assumption. But those massive amounts of data aren’t regulated or standardized, so the focus of volume shifts from what exists to what’s accessible, and that process of getting access is the first step of many when it comes to making external data production-ready.
The biggest shift in velocity is caused by the lack of standardization in external data. Velocity previously referred to speed, and it still does. But the nuance here is that external data shifts the meaning from proactive speed to reactive speed.
With internal data, companies maintain full control over how and when data is collected, and how it’s delivered. This meant that as quickly as organizations could gather data, they could begin analyzing it. But with external data, there’s an extra complex step–wrangling that external data into a format that’s compatible with your organization’s infrastructure. There’s data for anything and everything being gathered quicker than you can open a new browser window, meaning now you’re constantly reacting to new sources, formats, and events. The limitation on that speed is how quickly you can make that data production-ready.
With velocity, there’s an additional catch: onboarding external datasets takes longer because of regulatory scrutiny. It typically takes hedge fudges anywhere from 3-9 months to onboard a new dataset, partially because of the SEC and internal compliance reviews. Legal and regulatory reviews can slow down onboarding, so accelerants are needed elsewhere to keep up the pace.
Previously the only competition for speed was yourself–how quickly can you gather customer information to create a new product, web page, or service? Now, your competition is everyone else. Can you transform, analyze, and apply the latest COVID-19 data to predict changes in your supply chain before they happen, or before your competitors figure it out? Velocity has shifted from how quickly data can be produced, to how quickly it can be consumed.
The biggest change in variety is that it becomes a dependency on velocity when it’s related to external data. Previously, variety was determined based on the array of sources you used for data points. With internal data, variety is limited by your business’s capabilities. With external data, variety is infinite as new data sources are created each day.
What matters when it comes to external data’s variety is how it’s supported by velocity. Since there’s no longer a question of the amount of variety data has, the focus shifts to how much of that variety you can quickly access–in other words, if your velocity supports your desire for variety. If you cannot process new data sources quickly and efficiently, variety isn’t even a consideration when it comes to external data.
Each source also has its own variety of formatting, naming, and supporting information. If your organization can’t tackle those differences, variety is impossible to achieve at a meaningful speed with external data.
Something about a third party’s involvement tends to give things more an air of trustworthiness, which is why veracity changes from the source to the consumer with external data.
With internal data, people wanted to know that the data producer–also the consumer and analyzer–was reliable and honest. The importance was on if your data itself was trustworthy, but that’s shifted. With external data, the sheer quantity of it means it can be quickly validated by comparison. Additionally, technology (sometimes) is thought of as relatively unbiased and collects data without nuance.
But for external data use cases like ESG, the importance of veracity shifts from the data itself to how it’s used. For ESG data specifically, which can be used to determine if an organization is worth investing in for an assets manager, the process is key. The data is subjective by nature, so consumers of ESG data suppliers want to know how each data point was collected and why, followed by how it was analyzed, and within what parameters.
Sentiment analysis is another great example of this shift. There’s no question that Twitter collects and sells users’ data, and that data can be used by brands to determine how consumers feel about their brands based on the syntax of their Tweets. But the natural language and machine learning models applied can result in drastically different outcomes, depending on how the models were trained, and what their sources for training data were. The onus is no longer on Twitter for validating their data–anyone can log on and verify it themselves. Now the shift in veracity means the trustworthiness of the sentiment depends entirely on the transparency of the analysts and data scientists producing the results.
The four Vs of data aren’t going anywhere. They will still be taught in college engineering courses, considered (sometimes subconsciously) by analysts in their day-to-day work, and evaluated by product teams creating for big data.
But leaving them as-is without taking a fresh look at their meanings when the market shifts can stunt growth. By not reevaluating the four Vs with external data in mind, you’re preventing your business from harnessing the power external data can provide for making critical business decisions.
And that doesn’t just go for the four Vs–next time you’re referencing a framework you learned years ago, stop and think about what’s changed, and how you can address those gaps. It might just lead you to the next big thing–at least, that’s what we like to think happened when Crux was founded.


Not long ago, we observed here in our blog that the critical insights that drive business value come from data that is both (1) fast and (2) reliable.

This past year has been exciting, representing the dawning of a new age for artificial intelligence (AI) and machine learning (ML)—with large...

How do you get white-glove customer service from a major data supplier?