

What Cloud Marketplaces Do and Don’t Do
Not long ago, we observed here in our blog that the critical insights that drive business value come from data that is both (1) fast and (2) reliable.

An additional resource for your data engineering team.
When you turn on the faucet in your house, you expect water to appear, you use it, turn the faucet off, and move on. You usually don’t spend much time questioning where the water came from, how it was processed, if what you’re using came from more than one source, or if there will be water the next time you turn on the tap. The complexities of that simple action are hidden behind centuries of evolving technology around water processing, and you trust them to work when you need them to, even though the behind-the-scenes process is anything but simple.
External data, like water, is also very complex. It’s always flowing through the plumbing and comes in from a variety of sources. It could be recycled, from groundwater, a river, a well, a spring, or even a rainwater system. Because each of those sources are different, the cleaning and processing of that water is different each time to ensure you get the same end result every time you turn on the faucet–clean water. External data is the same–it can come from a public source, a supplier, internally within your business, from social media, web scraping, surveying, and many other places. To successfully use this data to drive intelligent business decisions, you need a successful plumbing system to deliver that data quickly and cleanly to you–just like water.
But in today’s data market, that’s often where the similarities to water stop. External data comes from a variety of sources, and there isn’t a true pipeline from source to consumption. The reality is that third-party data’s plumbing is less of a pipeline and more of a maze. Each data supply has its own sources, formatting, processing, and abilities, and no two are the same. Current data platforms only cover pieces of the puzzle, resulting in a complex external data tech stack that muddies your infrastructure.
But what if it didn’t have to be this way? If we had a streamlined external data pipeline to support efficient usage of third-party data, what would it look like? And better yet, what if one product could solve all of your data flow problems at once? To connect external data sources to your internal infrastructure successfully, your pipeline must address all the common frustrations with third-party data before it even enters your environment. An ideal solution should ingest data from any external source and distribute it to any destination, whether it’s a cloud, analytics platform, API, SFTP, or custom option.
This streamlined external data pipeline should have solutions for enterprise-grade security and scaling, curation, monitoring and remediation, quality, transformation, and entity matching. Removing any of these critical components can quickly turn your pipeline right back into a maze, and ensure that your data operations team spends 80% of their time on engineering and only 20% on data science. Utilizing this pipeline can switch that ratio, and allows external data to flow into your organization just as easily as water does when you turn on the faucet.
Reimagining the maze that is third-party data integration into the streamlined process it can be is easy in theory but more complex in practice. We call this pipeline the Crux data pipeline, not because it can’t apply to companies that don’t use Crux, but because we provide all the capabilities you need to implement this flow of external data into your organization. This pipeline is based on our AI-powered external data management platform. We help organizations visualize this new plumbing for data and bring it to life. Each phase of this pipeline has specific challenges, so it’s important to integrate an external data solution that addresses each individually to create a successful pipeline that works from beginning to end.
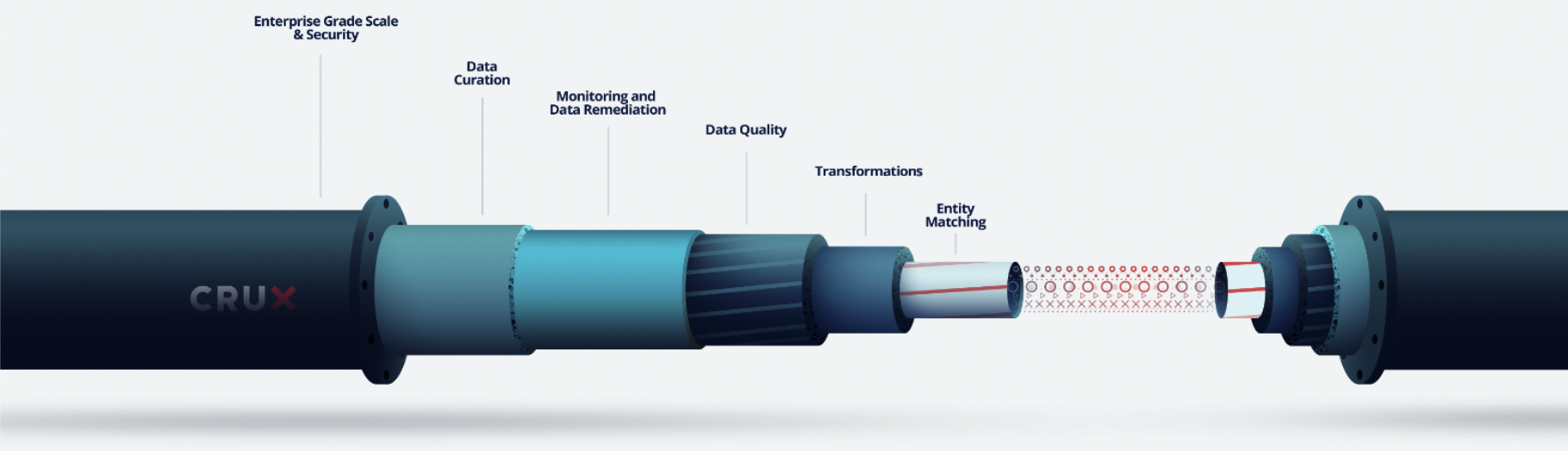
At Crux, we are committed to maintaining integrity and confidentiality for our customers, without sacrificing the ability to quickly scale. Crux’s platform is based on the NIST framework, and we are SOC 2 Type II certified.
Crux’s platform, Crux Deliver, is designed to be highly available through the use of highly resilient multi-region infrastructure and auto-scaling microservices. Crux Deliver is our core offering built to deliver and ingest any data source into any destination including API, SFTP, and cloud platforms.
External data is a great tool to use to make smart business decisions, but there’s a lot of work that goes into accessing those datasets. You have to research, implement, monitor, and format each new dataset you bring onboard.
Crux has two add-on features to combat these issues: Crux Discover and Crux Query. Crux Discover allows users to browse data and metadata within our platform. And with over 25k+ pre-populated datasets readily available you can begin exploring these new datasets hours after signing the entitlements. Crux Query then takes discoverability to the next level by getting in a layer deeper and providing querying within each dataset.
Benefits of data curation include:
Setting up a workflow to access external third-party data is only the beginning of a large amount of work that goes into accessing and maintaining third-party datasets. Keeping up with changes in your pipeline often requires tedious, custom work that monitors the flow of data for spikes, changes, or anomalies.
This is a huge hurdle for businesses with limited data engineers who should be spending their time on more complex and rewarding work. Crux Inform sends notifications for any data pipeline developments. This includes programmatic notifications of key events, late feeds, successful deliveries, supplier schema changes, and event custom developments.
Benefits of Crux Inform include:
Data quality is defined by Google as “the measure of how well suited a dataset is to serve its specific purpose.” But we think it goes a step further than just purpose–what shape the external data in when you get it, and what do you need to do to it to use it? Ingesting data into your pipelines usually requires periodic sampling, building and testing anomaly detection algorithms, building alert mechanisms, and more. This is not scalable and is required for each new dataset that you bring onboard, resulting in a lot of re-inventing the wheel.
Crux Verify offers customers the ability to define and create data quality checks based on battle-tested, metadata-derived metrics to confirm the external data meets their specifications. Crux Verify also enables anomaly detections to identify outliers and avoid common pipeline problems.
Its benefits include:
Once an external third-party data source is in the hands of your end-users, it has to be formatted, filtered, and otherwise modified to fit your organization’s needs. It’s a lot like getting new groceries. Going to the store and purchasing the items is step one, but once you get home to make them useful they must fit into your kitchen pantry where they belong. That second step is data transformation.
Data transformation is yet another part of the external data pipeline that can require tedious, manual work. Once the quality of your data is confirmed, then it’s time to make the square peg fit in a round hole. External datasets will need to be formatted, combined, filtered, shaped, calculated, filled, and more.
Crux Wrangle delivers production-ready third-party external data by enabling you to:
The most difficult challenge to overcome when it comes to external third-party datasets is entity matching. While it’s very likely your datasets contain the similar data fields, the odds that each dataset onboarded refers to those fields exactly the same are slim to none. For example, each dataset that refers to a location probably refers it any number of ways, like address, _address, ADDRESS, location, geographic_location, and anything else you can dream up. Matching all related entities to your internal naming standards is manual and tedious.
Crux developed Crux Match to accelerate this step by automating data entity matching across all data pipelines via our AI-powered cloud platform, Crux Deliver. Crux Match allows you to connect a variety of external data products to your internal reference datasets using an automated match engine that leverages a suite of machine learning models to optimize match coverage while minimizing false positives.
Benefits of Crux Match include:
The key to success with your third-party data pipeline is ensuring your organization has each critical piece of the pipeline in place. There are great tools on the market today that address specific pieces of the pipeline, but missing even one piece of the puzzle can cause a ripple effect–a blockage in your plumbing that stifles or infiltrates the flow of data.
Having every piece of the pipeline is only the beginning of a successful third-party data pipeline. The next step is confirming that each part of the process is centralized and ready to scale. One dataset is not the same as ten, and the amount of maintenance and operational work scales exponentially with an increase in the amount of external data flowing into your organization.
If you’re looking for help transforming your external data maze into a pipeline, Crux can support your team’s efforts. We can help you reimagine how third-party data flows into your organization, and bring that vision to life. Just like our water system has improved over time with new technologies, third-party data is rife for improvement, and it’s critical to improve its flow so your business can utilize it to drive better business outcomes.


Not long ago, we observed here in our blog that the critical insights that drive business value come from data that is both (1) fast and (2) reliable.

This past year has been exciting, representing the dawning of a new age for artificial intelligence (AI) and machine learning (ML)—with large...

How do you get white-glove customer service from a major data supplier?