

What Cloud Marketplaces Do and Don’t Do
Not long ago, we observed here in our blog that the critical insights that drive business value come from data that is both (1) fast and (2) reliable.
In the world of Data Engineering, the acronym “ETL” is standard short-hand for the process of ingesting data from some source, structuring it, and loading it into a database from which you’ll then use that data. ETL stands for “Extract” (ingest, such as picking up files from an FTP site or hitting a data vendor’s API), “Transform” (change the structure of the data into a form that is useful for you), and “Load” (store the transformed data into a database for your own use).
At Crux, where we are serving the needs of many clients, our approach is slightly different, designed both to gain the economies of scale that we can leverage as an industry utility, serving multiple clients across multiple sources of data, and to give individual clients the customized experience that they’d expect from a managed service to meet the needs of their specific use cases.
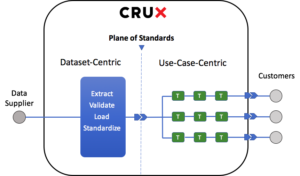
“EVLS TTT” stands for Extract, Validate, Load, Standardize, Transform, Transform, Transform… “Extract” here is the same as above (ingest data from its source). “Validate” means to check the data as it comes in to make sure that it is accurate and complete. If a data update fails any of the Validation tests we run on it, our Data Operators are notified and corrective action is taken immediately. Examples of validations include ensuring that an incoming data update matches the expected schema, ensuring the values in a column conform to expected min/max ranges (for example should numbers in this column always be positive), or making sure that enumerated types (such as Country) fall within the accepted set of values. Validations also test data coverage: does the date range in the update conform to what is expected? If the dataset is supposed to cover companies in the S&P 500, does it in fact cover all those companies, no more, no less? Validations also look for unlikely spikes and jumps in continuous data, identifying outliers for closer examination by our Data Operators.
“Load” is as above (store the data into a database). “Standardize” is a set of special Transformations that get the data into an industry-standard form that makes the data easy to understand, easy to join across multiple datasets from multiple vendors, easy to compare, etc. Examples of standardization include data shape (such as unstacking data and storing it all as point-in-time), entity mappings (such as security identifiers), and data formats (such as using ISO datetimes). We do of course store the raw data exactly as it comes from the data supplier, which customers can access as easily as the cleaned/standardized version.
We leave a gap between the “S” and the “TTT…” because at that point the data has been loaded, checked, and put into a form that should suit the needs of most customers as is. We call this spot “the Plane of Standards”. The “TTT…” are any number of specific Transformations that are required by individual clients to suit their own use cases (mapping to an internal security master, joining several sets of data together, enriching data with in-house metadata, etc). Those Ts give clients the ability to have a customized experience when using Crux.
The goals of all this are to be able to gain economies of scale and mutualize the effort and cost of the commoditized parts of the process, making it cheaper and faster for everyone, while still giving clients the ability to get a bespoke output to serve their individual use cases. Crux does not license, sell, or re-sell any data itself: Data Suppliers license their products directly to customers, maintain direct relationships with those clients, and control who has access their data on the Crux platform. We work in partnership with Data Suppliers to help make their data delightful for our mutual clients.

Not long ago, we observed here in our blog that the critical insights that drive business value come from data that is both (1) fast and (2) reliable.

This past year has been exciting, representing the dawning of a new age for artificial intelligence (AI) and machine learning (ML)—with large...

How do you get white-glove customer service from a major data supplier?