.svg)
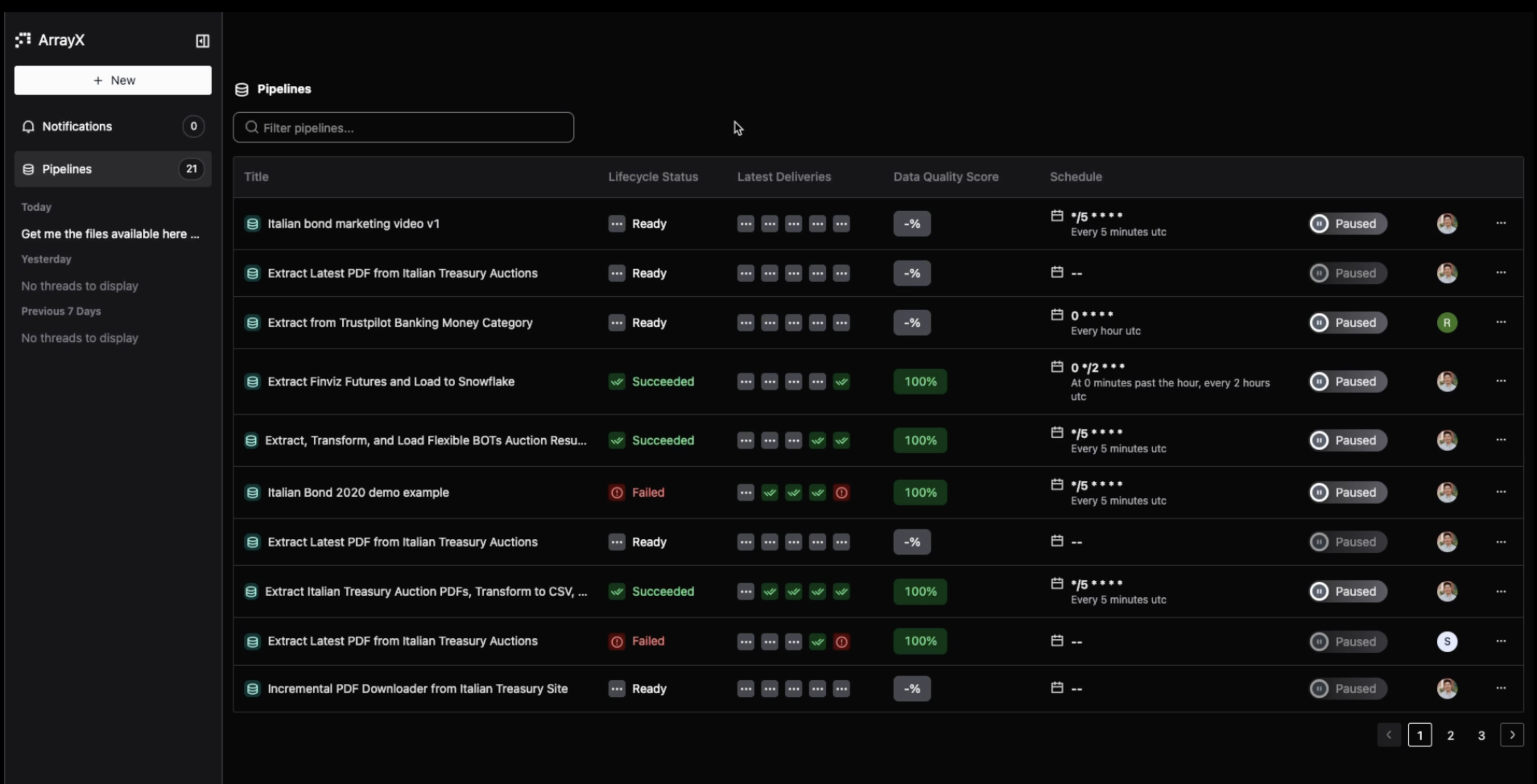
For years, the hardest part of working with data hasn’t been analysis - it’s everything that comes before it. Pipelines break, scrapers fail, schemas drift, and teams spend days rebuilding what should already work.
We built ArrayX by Crux to change how that work gets done.
ArrayX is an agentic AI platform built for self service, turning natural language into resilient, self healing data pipelines. It’s built to understand what data you need, where to find it, how to keep it flowing, and how to guarantee its quality - all without manual code or maintenance.
With ArrayX, you start with intent. You describe the data you want in plain English - whether it lives on a website, inside a PDF, behind an API, or across multiple feeds.
You can see how this comes together in practice in the short demo below - from prompt to live, self-healing pipelines in minutes.
ArrayX’s AI-native pipeline builder then handles the rest. It intelligently locates and interprets the data, even across complex, unlabeled sources. On a page full of dense trading tables, pricing grids, or product listings, ArrayX can identify the relevant sections automatically and extract exactly what you need.
It iterates to your target schema, validates the output, and builds a reusable pipeline that can be scheduled, monitored, and delivered anywhere - Snowflake, Databricks, BigQuery, S3, etc.
Unlike traditional scraping or ETL tools, ArrayX doesn’t stop once the pipeline is built - and it isn’t limited by rigid, pre-set rules. It keeps thinking.
Every pipeline runs through an enterprise-grade execution engine with automated issue detection, real-time in-app and email notifications, and full visibility into every run.
If a source changes, ArrayX’s self-healing logic automatically triages and repairs the pipeline - adjusting for schema drift, missing fields, or upstream logic before the issue becomes a failure. It doesn’t just retry; it understands why something broke and fixes it intelligently, in place.

Under the hood, ArrayX is engineered for serious operational reliability.
This foundation means ArrayX isn’t just fast - it’s trustworthy. It’s designed to meet the security, governance, and audit standards of global enterprises across every vertical.
Data quality shouldn’t require a separate platform or custom scripting. In ArrayX, it’s built in.
Users can define validation logic using natural language rules - things like “every record must include a date, region, and price greater than zero.” ArrayX enforces those rules automatically, applying deterministic checks on every run to ensure accuracy and consistency.
Every step - from extraction to delivery - is logged and traceable, creating full lineage and audit trails for compliance teams.
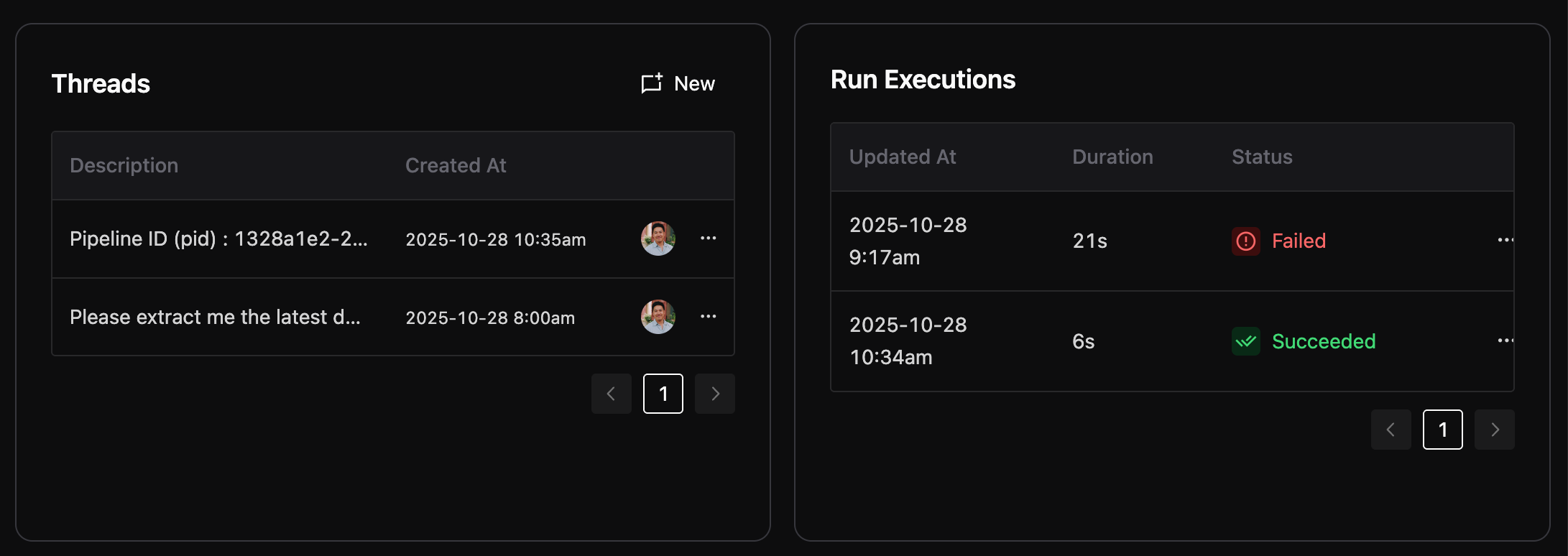
The first frontier for ArrayX’s agentic AI capabilities is web data extraction, where pipelines are most prone to breakage and manual effort.
Instead of coding fragile scrapers, users simply prompt ArrayX. It locates the data, formats it, validates it, and keeps it alive with real-time self-healing. The result is reliable web data delivered continuously - clean, compliant, and ready for modeling or analytics.
In early pilots, teams using ArrayX have:
Those gains don't come from shortcuts, but from intelligence - giving AI the agency to build, manage, and maintain what used to require constant human oversight.
ArrayX isn’t a single-use scraping tool. It’s the start of a new data architecture - one where agentic AI manages the full lifecycle of external data pipelines, across industries and use cases with self-service at the center.
It’s built to scale beyond web data to any source, any format, and any destination - keeping the world’s data pipelines alive, compliant, and ready for insight.
See how intelligent data extraction that fixes itself end to end actually works. Learn more here or request a demo.















