Financial institutions aren’t suffering from a lack of data. They’re suffering from what happens after the data shows up. Market data spend continues to hit record highs, and alternative data is growing at a staggering pace.
New sources, new signals, new vendors - on paper, this should be a golden age for data-driven alpha. In practice, many firms are hitting a wall. Onboarding takes months. Pipelines break unexpectedly. Formats drift. Engineers spend more time fixing data than using it. That tension - between exploding demand and operational reality - is what we mean by the external data maze.
This was the focus of our recent webinar, Navigating the External Data Maze: Challenges and Breakthroughs for Financial Institutions. In this post, we’ll summarize the core ideas. If you want the full discussion and real-world examples, you can watch the on-demand webinar here: 👉 Watch the webinar
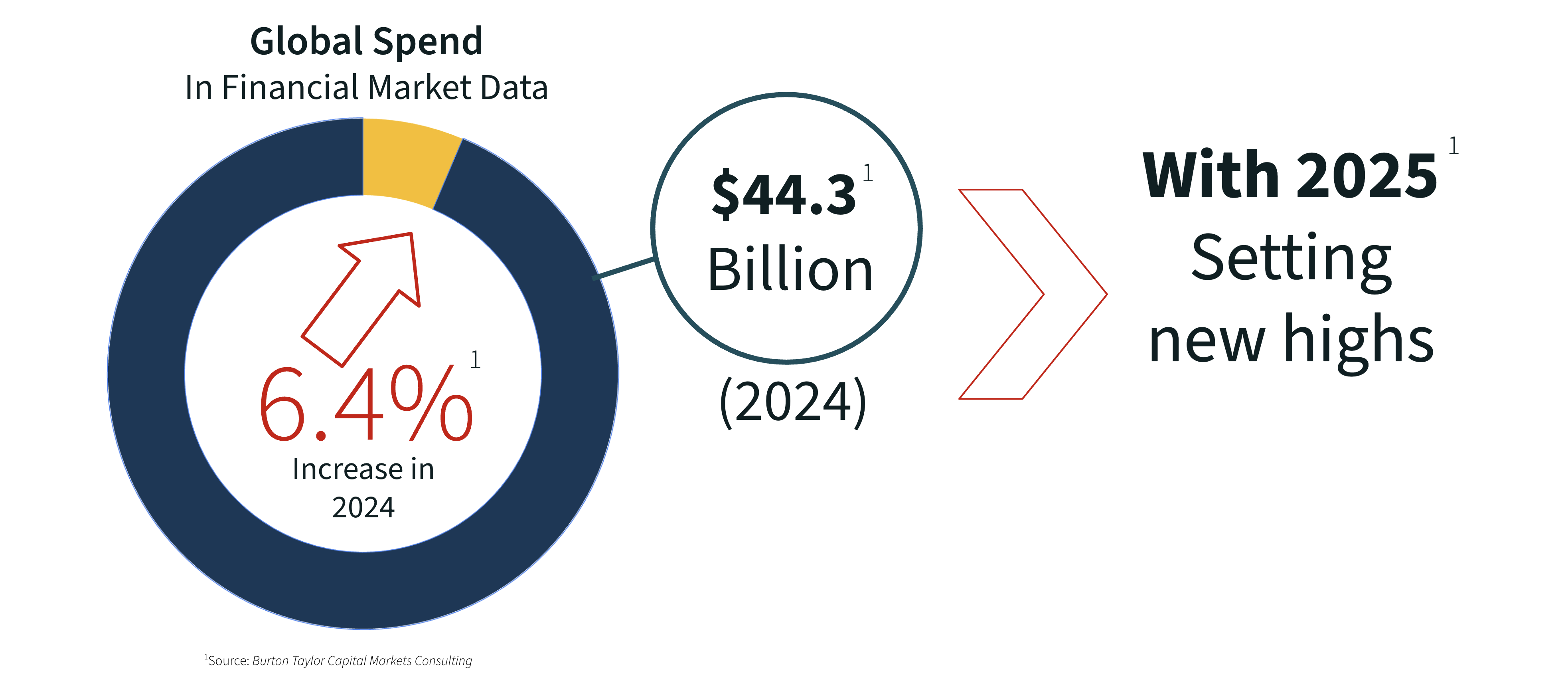
More spend, slower progress
Global financial market data spend keeps rising, but growth is starting to flatten. That’s not because firms don’t want more data - it’s because every new dataset carries integration cost, operational risk, and long-term maintenance overhead.
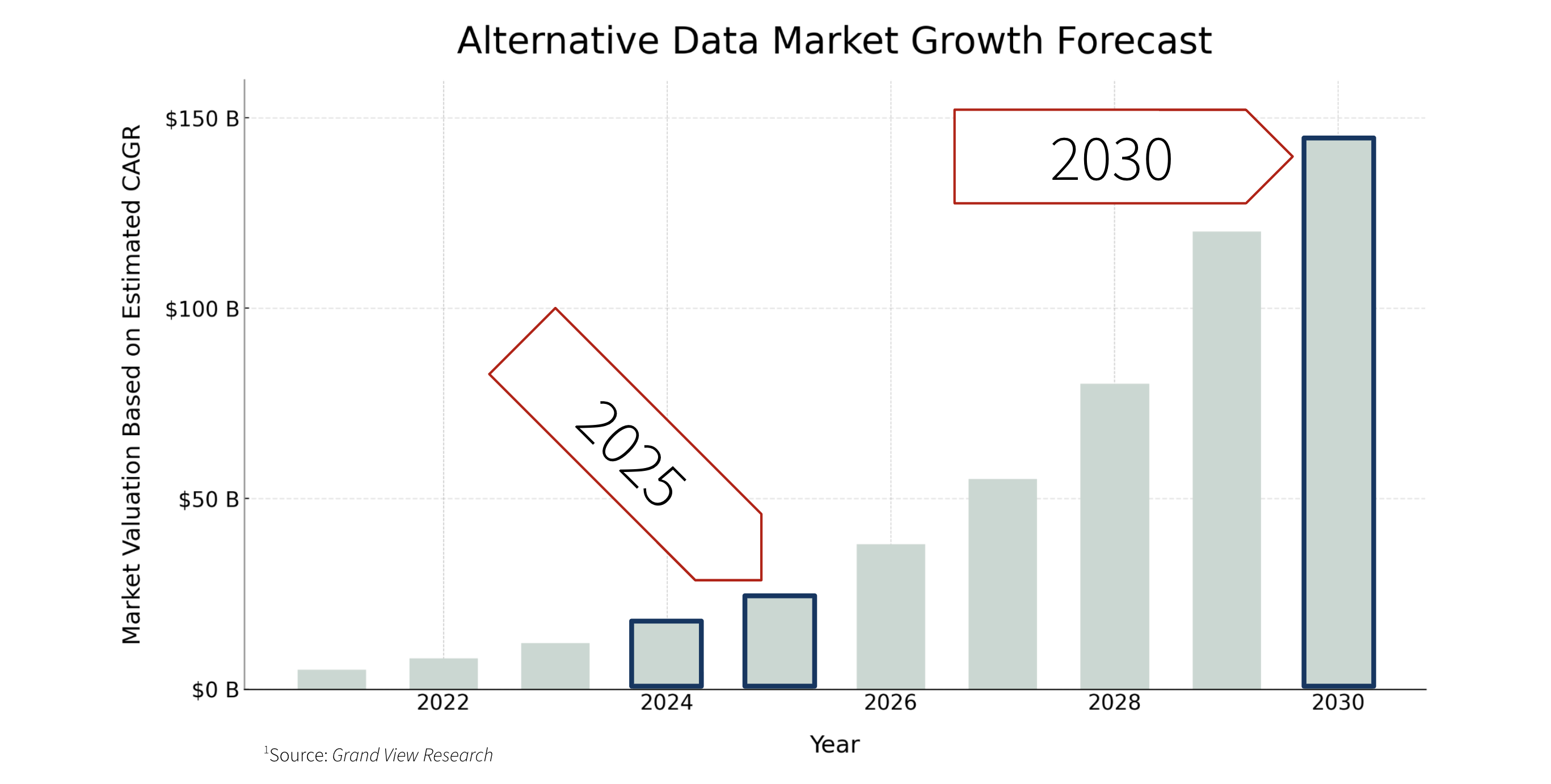
At the same time, alternative data has fundamentally changed the landscape. Firms are no longer limited to traditional pricing, fundamentals, and research. Web data, public data, machine-generated data - entirely new categories of signal are now in play. The opportunity is massive. So is the complexity.
Breadth creates advantage - if you can handle it
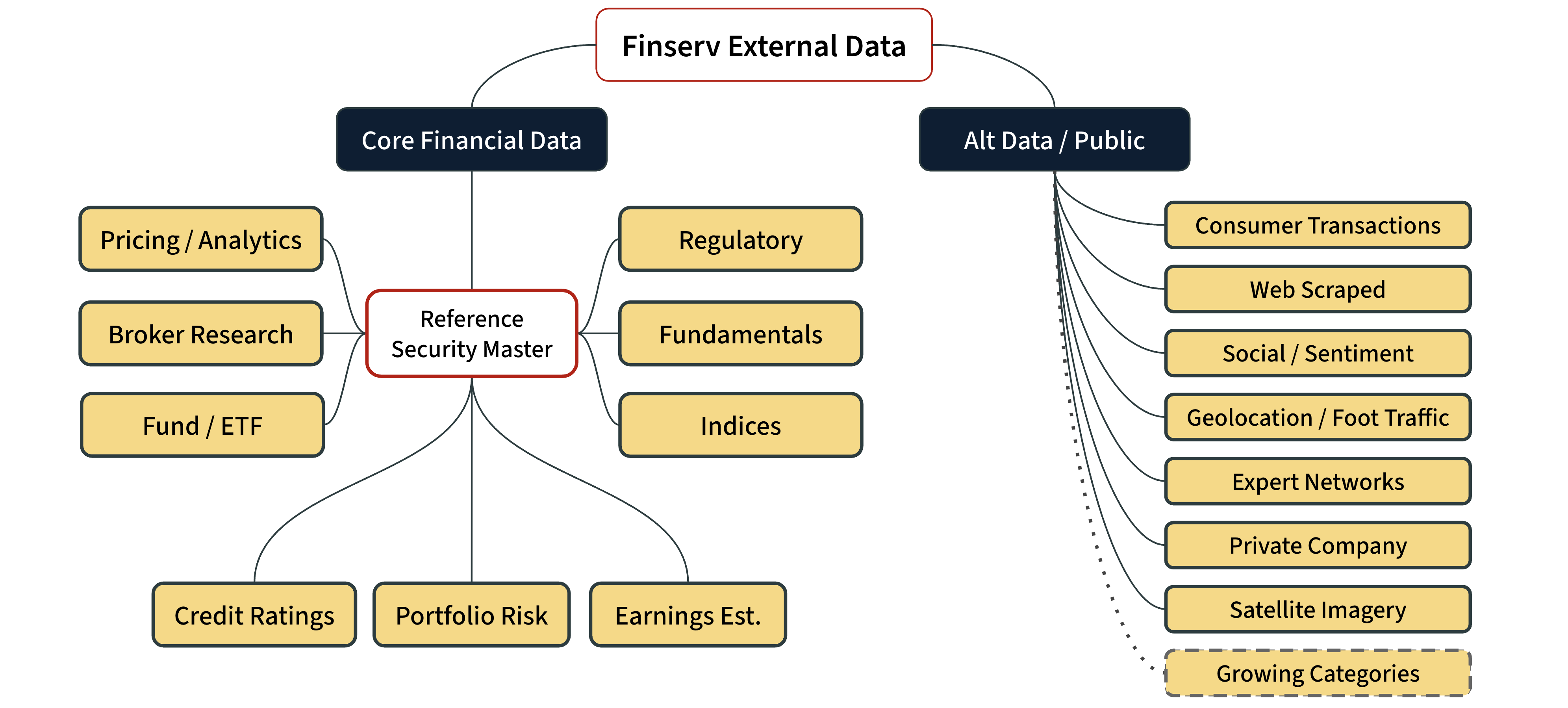
No serious investment strategy runs on a single vendor. Firms need decades of history, multiple perspectives, and varying levels of granularity. That means stitching together Bloomberg, Refinitiv, FactSet, MSCI, niche providers, and public sources. The competitive edge doesn’t come from buying that data.
It comes from integrating, normalizing, enriching, and delivering it reliably - at scale. That’s where many teams struggle.
The real goal: model-ready data
In the webinar, we made a clear distinction:
External data is any data that originates outside your organization.
Model-ready data is data that is structured, high quality, discoverable - and delivered on time.
That last point matters more than most teams admit. Data that arrives late, incomplete, or inconsistently might technically exist, but it can’t drive decisions or models when it matters.
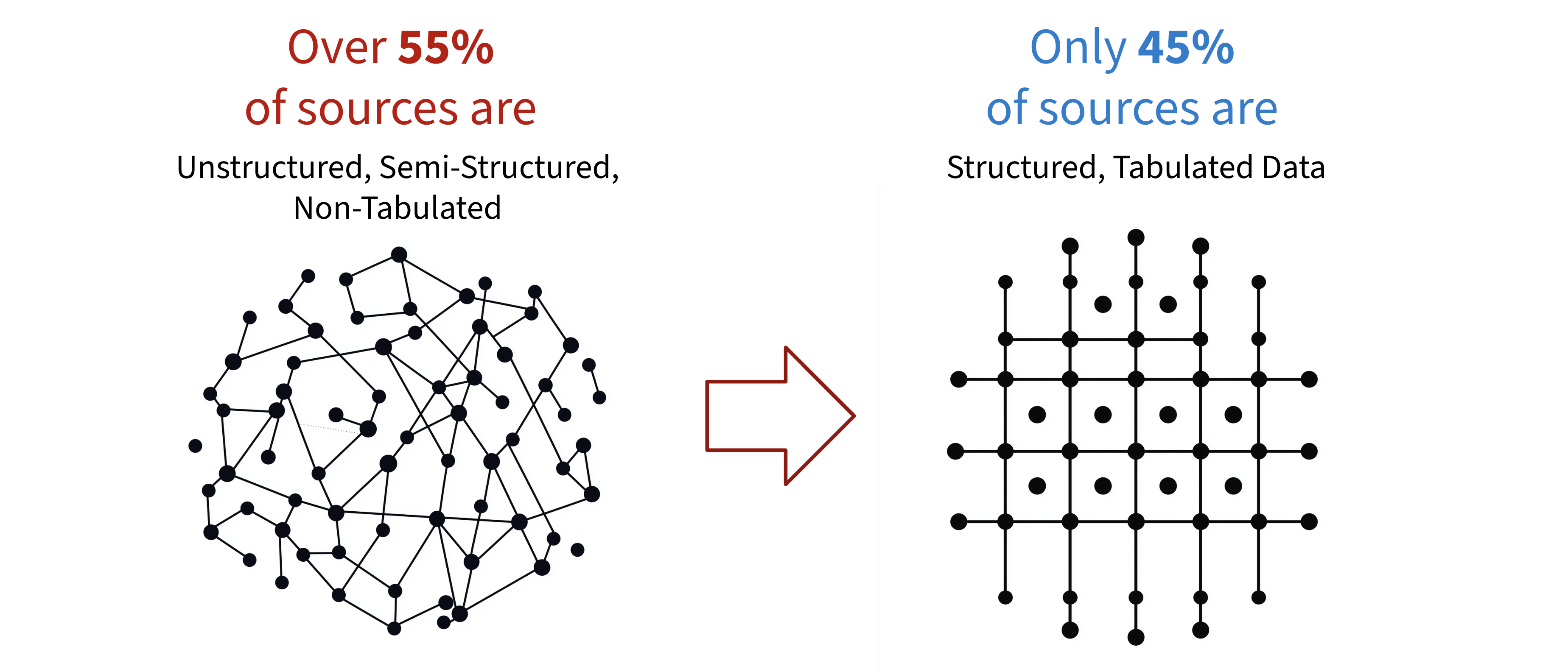
In reality, most external data does not arrive model-ready. Over half of sources are still unstructured or semi-structured, forcing teams to spend enormous effort just “unblocking” data before it can be used.
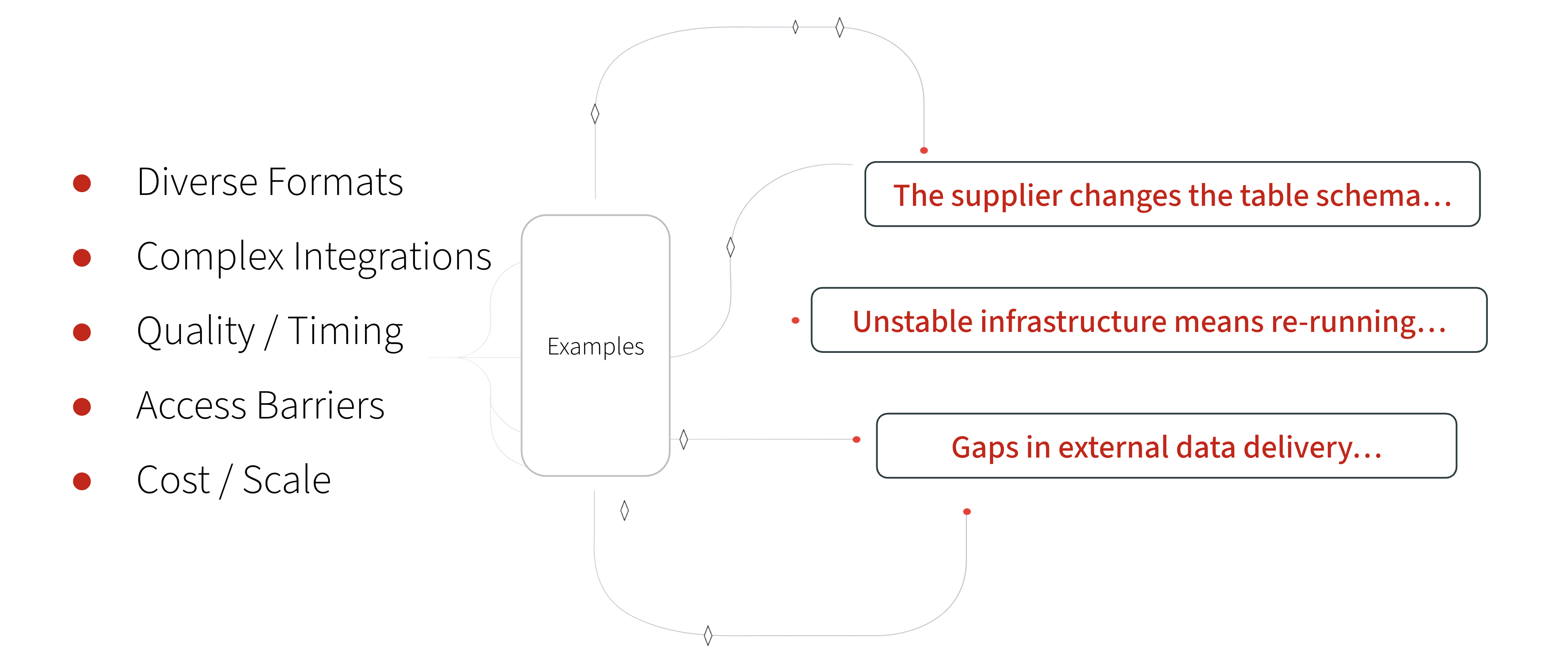
Why teams get stuck in the maze
What breaks isn’t one thing - it’s everything at once:
Data arrives via FTP, APIs, emails, portals, or web scraping
Schema changes are frequent and often unannounced
Context dates, corrections, holidays, and frequency logic are fragile
Legal, procurement, and security reviews slow onboarding
Costs balloon as pipelines multiply and engineers firefight issues
None of these problems are rare. They’re the daily reality of operating external data at scale within hedge funds, and other financial institutions that thrive on timely data.
What the most effective teams do differently
The firms that break out of the maze stop treating external data as an ad-hoc engineering task. They centralize it. They standardize it. And they design for scale from day one.
In the webinar, we discussed what “good” looks like in practice:
Faster onboarding - measured in weeks, not months
Resilient pipelines with built-in monitoring and recovery
Lower operational risk and fewer downstream surprises
Data scientists spending time on signal, not plumbing
This is where operational alpha shows up - not as a buzzword, but as fewer failures, faster access, and better use of expensive talent.
From summary to substance
This post is simply a snapshot. The webinar goes deeper - drawing directly on experience from large financial institutions operating thousands of external data pipelines, and unpacking how teams are adapting to the realities of alternative and public data at scale.
If external data reliability, timeliness, and cost are becoming constraints for your organization, this discussion will help:
👉 Schedule a Demo or Contact Us directly and we’ll be happy to discuss a free report and external data assessment fitting your use case.
Conclusion
As we look to the future, Crux remains at the forefront of data innovation. By streamlining integration, expanding access to alternative data, prioritizing governance, and driving sustainability, we’re empowering businesses to make smarter, faster decisions.
2025 is shaping up to be a transformative year, and we’re excited to continue helping organizations unlock the true value of their data. Whether you’re looking to optimize your current processes or explore new opportunities, Crux is here to help you succeed.
Explore Crux’s offerings today and see how we can empower your data-driven decisions.
.svg)













.png)