Efficiency for Model-Ready Data - And the Scale Required to Deliver It
Operational Alpha: The Key to Success in 2025
Daniel Petzold
Every firm eventually hits the same decision point: Do we build the full stack of model-ready external data in-house, or do we rely on a managed service built to deliver it at scale?
Many firms want full internal control, but cost, talent shortages, and the growing complexity of external data pipelines make that approach increasingly unrealistic. As datasets expand, update schedules accelerate, and AI models demand cleaner input, firms find themselves investing more in infrastructure plumbing than in actual value creation.
In this post, we’ll break down the real hierarchy behind model-ready external data, the engineering maturity curve that quietly governs what firms can handle internally, and why the inflection point often comes far earlier than expected.
The Hidden Cost of Model-Ready Data
Model-ready data sounds straightforward: get the data in, clean it, make sure it arrives on time, and feed it into your models. But when you’re dealing with diverse, constantly changing external suppliers, this becomes one of the most operationally demanding layers of your entire AI stack.
Firms often underestimate the sheer amount of engineering discipline required at the foundation. In fact, most challenges in modeling or analytics originate in the layers below - the layers teams don’t actually want to spend time on, but absolutely must get right.
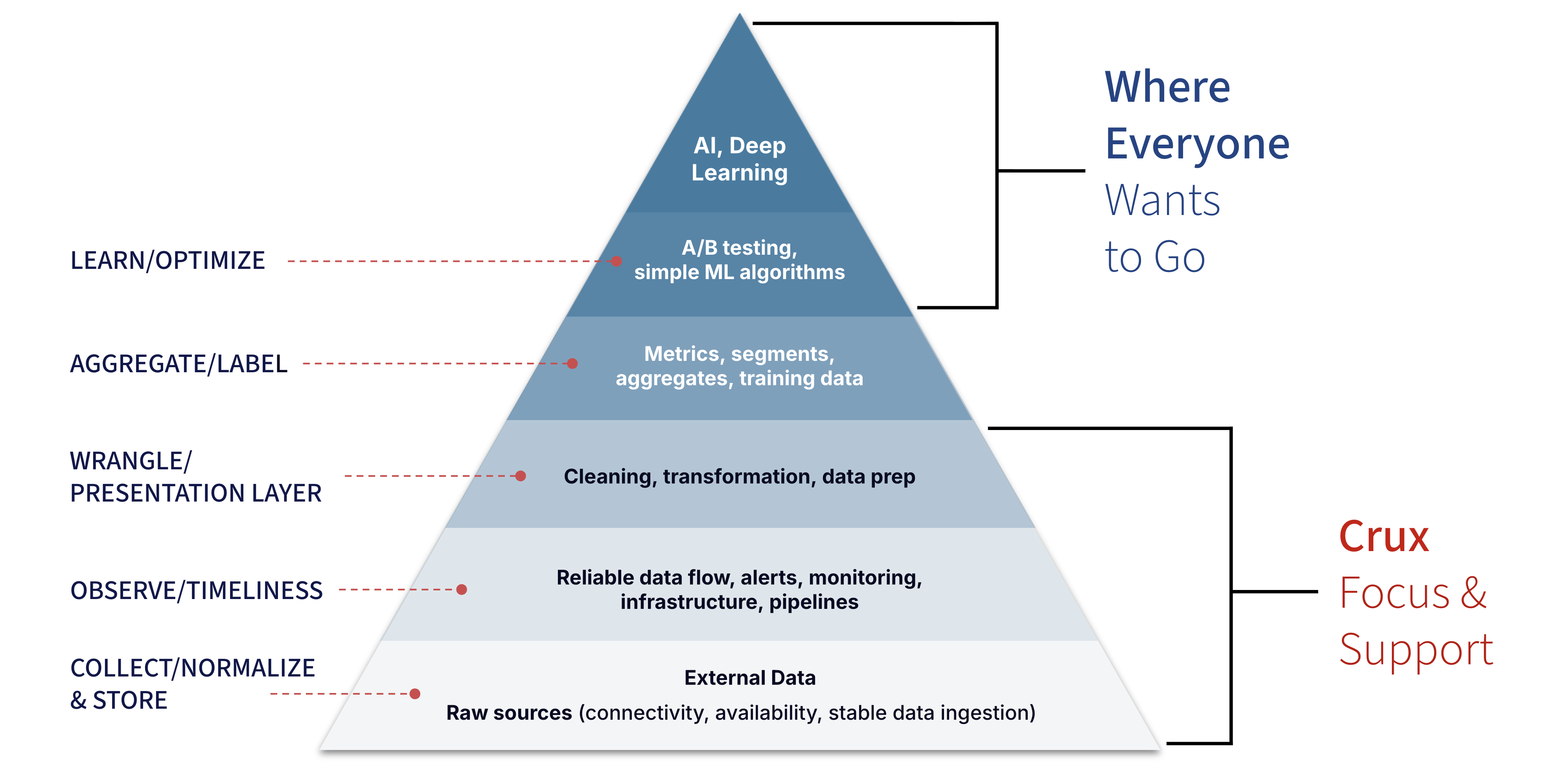
The Model-Ready External Data Hierarchy of Needs
Before you get anywhere near models and outcomes, you must conquer this pyramid:
Crux focuses on these foundational layers:
1. Collect / Normalize / Store Connect to messy external suppliers, handle raw formats, versioning, credential churn, and ensure stable ingestion at scale.
2. Observe / Timeliness Track delays, failures, schema drift, outages, and timeliness issues - before they impact downstream models or reporting systems.
3. Wrangle / Presentation Layer Transform, clean, map, and prep data into the formats that analytics, quant, and AI teams rely on.
Only after those foundations are solid can internal teams shift to the layers everyone wants to spend time on:
4. Aggregate & Label
5. Learn & Optimize
6. AI & Deep Learning
The painful truth most firms learn too late is this: These upper layers are only as good as the lower layers - and the lower layers are where scale, complexity, and cost explode.
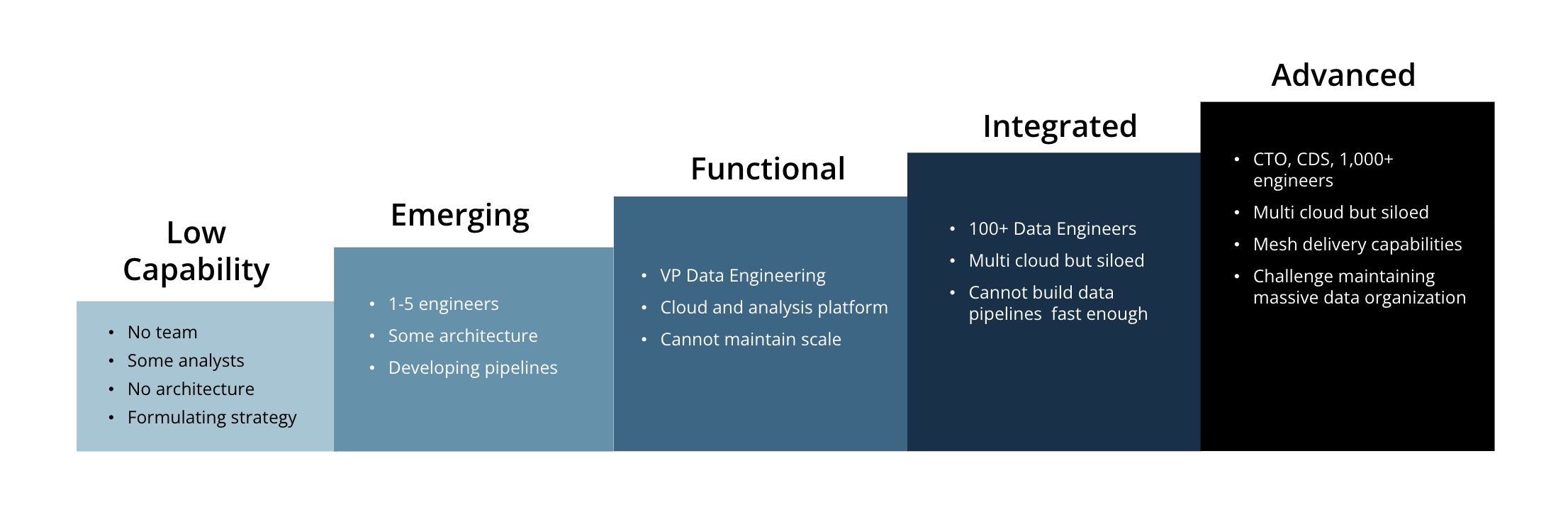
Where Teams Break: The Data Engineering Maturity Curve
The belief that “we’ll just build this internally” typically collides with operational reality somewhere between the Emerging and Functional stages of maturity:
Low: no team, scattered analysts
Emerging: a few engineers handling one-off pipelines
Functional: leadership in place and a cloud platform built, but the team can’t keep up with scale
Integrated: 100+ engineers and still not onboarding external data quickly enough
Advanced: 1,000+ engineers, multi-cloud, and still battling SLA failures and pipeline fragility
The breaking point almost always occurs at the Functional stage, when firms realize that the effort required to reliably ingest and maintain external data pipelines is consuming capacity that should be going toward models, analytics, and new products.
Crux Managed Service as the Solution
Sphere by Crux - Managed Service exists to take the hardest, least differentiating, and most operationally burdensome layers of external data - the bottom of the pyramid - and make them turnkey.
Crux makes external data model-ready, reliable, and production-grade with rapid onboarding, automated data profiling, schema inference, continuous validation, and around-the-clock monitoring. With 5,500+ functional data products and 200+ pre-integrated financial sources accelerates discovery and trialing, Crux’s Health Dashboard brings full transparency to timeliness, availability, and pipeline health.
From corrupted files and dynamic URLs to vendor-side schema changes, API failures, credential rotation, and deeply nested formats, Crux absorbs the operational load that typically overwhelms internal data engineering teams. With GitOps deployment via Crux’s ODIN spec and vendor-side triage handled directly, teams receive consistent, dependable model-ready data - without building the machinery themselves.
A Faster, Leaner, More Competitive Organization
Once the foundational layers of external data are handled by Crux, the entire organization becomes more efficient. Engineering teams regain the capacity to work on higher-value initiatives instead of digging through broken ingestion jobs or constantly debugging pipelines. Data scientists and quants finally get stable, versioned, fully normalized inputs - eliminating the silent churn and rework caused by irregular updates or schema drift. And business teams can launch new funds, new models, and new products with far shorter cycle times because data onboarding no longer becomes a months-long constraint.
The risk profile of the organization improves as well. Instead of reacting to late data, failed updates, or missing files, teams benefit from proactive monitoring, transparency into timeliness, and consistent SLA alignment. The operational chaos that often surrounds external data becomes controlled, visible, and managed. Models run on predictable inputs, not guesswork.
Perhaps the biggest shift is on the bottom line. By eliminating the need to scale engineering headcount linearly with the number of external sources - or worse, overprovision engineering capacity just to keep systems stable - firms can redirect budget toward areas that generate competitive advantage: research, client analytics, feature development, and AI innovation. Crux provides elastic data engineering capacity without the fixed cost, allowing firms to grow their external data footprint without growing their operational burden.
Ultimately, the outcome is simple: teams move faster, build smarter, and spend more time on the work that separates leaders from everyone else. With a stable, reliable foundation for external data in place, the ceiling on what the organization can build - and how quickly it can adapt - rises dramatically.
As we look to the future, Crux remains at the forefront of data innovation. By streamlining integration, expanding access to alternative data, prioritizing governance, and driving sustainability, we’re empowering businesses to make smarter, faster decisions.
2025 is shaping up to be a transformative year, and we’re excited to continue helping organizations unlock the true value of their data. Whether you’re looking to optimize your current processes or explore new opportunities, Crux is here to help you succeed.
Explore Crux’s offerings today and see how we can empower your data-driven decisions.
.svg)