

 Scout Scholes
Scout Scholes
Crux Supply Chain & ESG Whitepaper
Learn what Cannon Valley Research is all about directly from Jo Janssens in conversation with Crux Informatics CEO, Philip Brittan.“Crux offers data...

A comprehensive guide to understanding the economics of external data Integration to more accurately calculate the true costs of dataset integration
There’s a tremendous thirst for new external datasets to help fuel advanced analytics programs combining internal and external data sources. The exponential value of integrating these data sources looks like 1+2=10. The insight gleaned from combining a business’s critical data with third-party data such as financial market data, sustainability metrics, benchmarking data, weather information, etc. empowers decision-makers to address the blind spots, better anticipate trends, mitigate risk and gain a competitive advantage.
Yet, this level of data integration has its challenges. The difficulties and expenses often arise when it comes to integrating, supporting, updating, and harmonizing external data throughout its lifecycle. This is not a download-and-forget-it scenario. Data integration costs are like an iceberg. The visible part includes the cost of purchasing and analyzing the data; however, the unexposed portion that greatly exceeds these costs is the ingestion and maintenance phases which cost more than the initial procurement. Third-party data must continually be updated and maintained to provide the utmost value.
While 92% of data leaders cite onboarding more external data as a near-term priority, few have a clear sense of the cost of external dataset ownership. Research from Crux shows that businesses are underestimating their data pipeline costs by 35% - 70%. This oversight becomes more damaging as organizations rush to scale the volume of the external data they ingest.
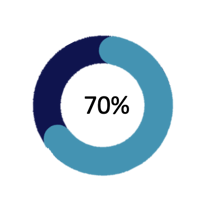
Companies are underestimating their data pipeline costs by 35% - 70%
The Challenge of External Data Cost Attribution
Why are businesses struggling to understand the costs of their external data pipelines? There are a few key reasons. First, they tend to focus on the cost of a data engineer in the creation of new data pipelines and ignore all the significant costs -- dataset acquisition, operations, and maintenance that data leaders fail to understand and factor into the cost analysis or investment needed.
The second is a lack of centralization. In large enterprises, each department or division operates its own data pipelines. Without a consistent way to analyze and calculate the costs of building and maintaining those pipelines, it’s natural businesses would miscalculate their costs as they rush to scale their external data integration efforts.
Lastly, there’s a lack of standardization. There’s no standardized terminology for often-used words like “dataset” which means different things to each data stakeholder and supplier, which further complicates planning and budgeting. And there is no standard framework for building the cost analysis for the lifecycle of a data pipeline. When you dissect the end-to-end activities associated with identifying, onboarding, curation, managing, and maintaining datasets, it becomes obvious that there’s no need to invent a new model to calculate the lifecycle of data pipelines. The similarities between software development and support parallel data pipeline development and support.
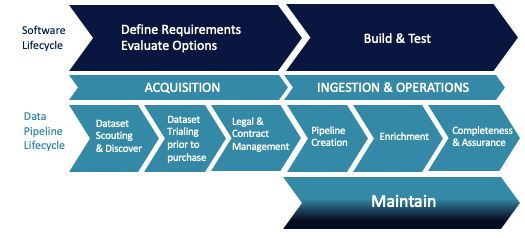
For an explanation of how data pipeline economics parallels software development, download the report.
A Comprehensive Model for External Dataset Economics
The first step in understanding the total cost of your external data pipelines is to acknowledge that a data pipeline has a long and complex lifecycle over a period of years and that there are significant costs attributed to each stage of that lifecycle from acquisition to ingestion and operations to maintenance.
ACQUISITION COSTS
The data acquisition process is a seminal phase of this external dataset process. It is where quantitative analysts, scientists, and data scouts not only procure datasets, but also trial them to ensure they will be a good fit and will satisfy the business’s requirements. The costs in this pre-ingestion phase can be quite high, even though the actual integration hasn’t even started yet. On average expect 15-30% of the total costs.
INGESTION & OPERATIONS
Once the third-party data is trialed, proven to be worthy, and then acquired, it needs to be ingested into the organization through the development of a data pipeline from the data provider to your internal environment. This is a highly complex phase as the new data isn’t often designed in a manner that is a one-to-one fit with existing datasets. A certain level of unpackaging, normalization, quality checking, data platform development, and ongoing dataset operations work must occur - and this requires a significant time commitment from your data engineers. A good portion of their daily responsibilities must be allocated to this process to ensure program success. It is not uncommon for the total cost over time to be 45-55%.
MAINTENANCE
Third-party data is a living, breathing entity that can provide ample ongoing value if its integrity is maintained. An often forgotten phase of this entire process is the maintenance phase, where businesses must correct data fields, make minor schema changes, create new frames and merge historic structures with the new ones. This stage cannot be overlooked and can incur significant costs if the first two phases aren’t handled correctly.
Drawing from the long history of application management research, a good starting figure to calculate the cost of data pipeline maintenance is 20% of the total build cost per year. This number will fluctuate based on several factors, including how rigorous your data vendors are about communicating change.
Now that the costs have been identified you can begin to assemble a comprehensive model for calculating the total cost of data integration. The below table summarizes the costs, stakeholders needed at each step in the dataset pipeline integration project, the resources needed to support the effort, and the total cost over time.
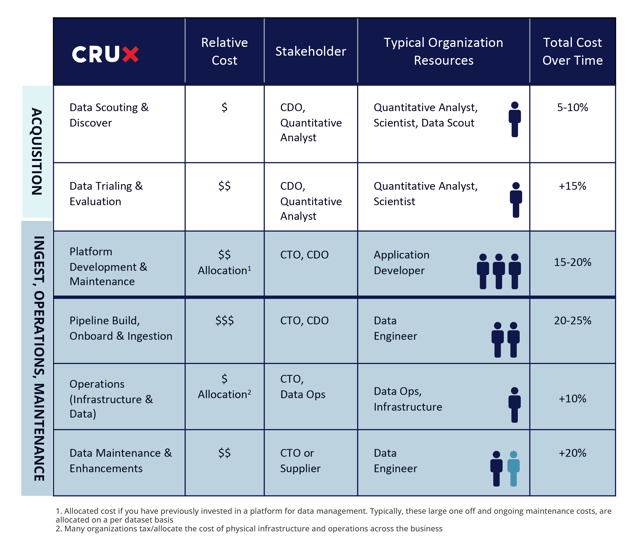
For more detail, refer to The True Costs of Dataset Integration The report guides how to make these calculations and provides some examples as you apply a cost model across multiple years and the cost implications associated with this prolonged view.
Driving cost savings in your external data strategyOnce you have a handle on your costs, you will be surprised at the financial implications. These cost projections can be daunting, especially as organizations rapidly expand their portfolios to integrate new ESG (environmental, social, and governance) data, mitigate supply chain disruption, and meet the challenge of increased competition.
Eventually, scaling in-house resources becomes too expensive, and at what risk? For most organizations, scaling data operations means either growing your team with new hires or outsourcing pieces of the process, resulting in a fractured and inefficient data supply chain. Many enterprises seek a service provider to supplement their data engineering staff to scale external data integration while offsetting the costs of building, operating, and maintaining their datasets.
If your enterprise relies on external data from various data sources and you anticipate your needs growing, you need an affordable solution that will allow you to scale data while reducing your overall integration costs and accelerating access to new data sources to position your organization for greater agility and competitive advantage. At Crux, help organizations reduce the cost of getting access to new data so that your team can focus on what they do best, driving business value.
Schedule a meeting to discuss your data pipeline TCO and we can identify ways to reduce your data pipeline lifecycle costs while mitigating risk in your growth strategy.
Crux is the leading provider of external data integration solutions for organizations looking to integrate, support, and transform external datasets. The company’s cloud-native data integration technology accelerates the ingestion, preparation, observability, and ongoing delivery of any external dataset into any destination, including Amazon, Google Cloud Platform, Microsoft Azure, and Snowflake. Using Crux, clients receive quality data in the right place, in the right format, and at the right time. The company combines best-of-category technology, world-class services, and deep-rooted expertise gained from over 25,000+ successful onboarded datasets. Our objective is to support the full scope of a customer’s external data pipeline lifecycle in a cost-effective manner.
To learn more about Crux and its data engineering and operations managed services, contact us.

Learn what Cannon Valley Research is all about directly from Jo Janssens in conversation with Crux Informatics CEO, Philip Brittan.“Crux offers data...

Supplier Spotlights highlight Crux's partners and shine a light on their unique data product offerings.

Supplier Spotlights highlight Crux's partners and shine a light on their unique data product offerings.